Research
5 years experience in:
- Experimental design and hypothesis testing.
- Collecting qualitative and quantitative data.
- Data interpretation and analysis.
- Using data visualization to communicate results to a wide audience.
I'm a PhD student at the University of Minnesota in the GroupLens research lab. My advisor is Joseph A. Konstan.
I have broad interests in human-computer interaction, machine learning, and probabilistic (bayesian) modeling, but my research focus is on recommender systems. My PhD work revolves around the following themes:
S. Thomas Christie, Daniel Jarratt, Lukas Olson, and Taavi Taijala. 2019. In Proceedings of the 12th International Conference on Educational Data Mining (EDM '19), 6 pages.
Schools across the United States suffer from low on-time graduation rates. Targeted interventions help at-risk students meet graduation requirements in a timely manner, but identifying these students takes time and practice, as warning signs are often context-specific and reflected in a combination of attendance, social, and academic signals scattered across data sources. Extremely high caseloads for counselors compound the problem. At Infinite Campus, a large student information system, we have modeled the statistical relationships between student educational records and enrollment outcomes, using de-identified records and in-system analysis to guarantee student data privacy. We integrated a context-sensitive school dropout early warning system into our product that provides timely, accurate, and actionable risk scores to counselors. Our machine-learned solution provides best-in-class predictive quality, daily updates, and four category scores designed to highlight the impact of a range of signals on a student's dropout risk.
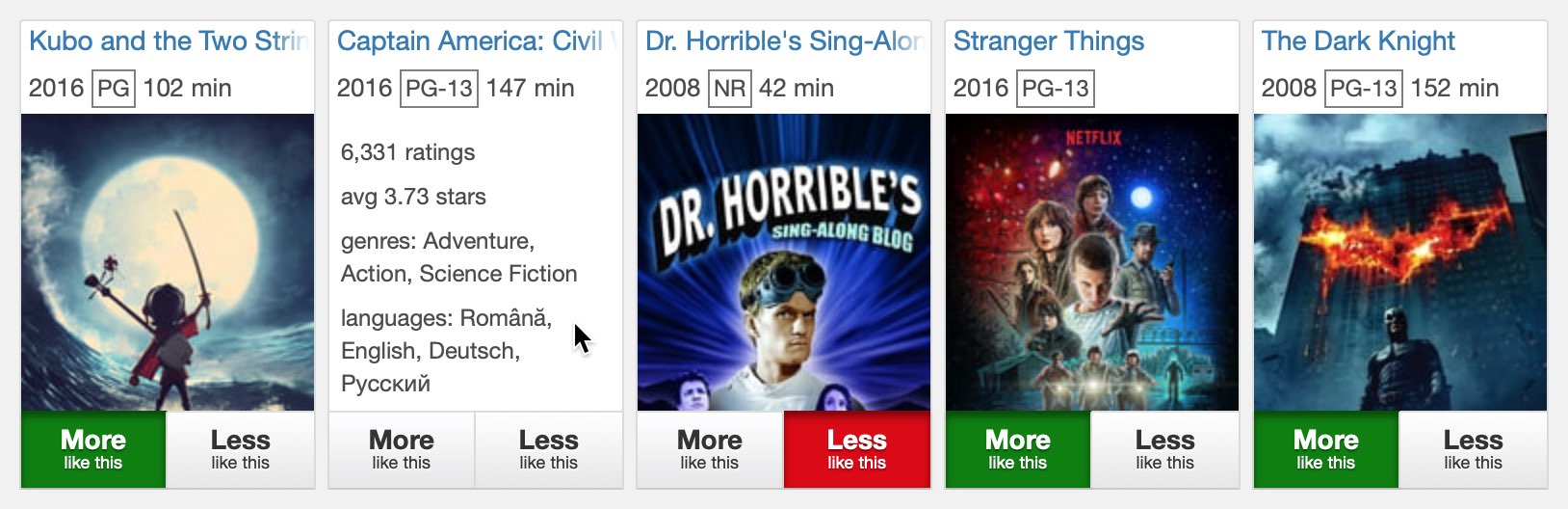
Taavi T. Taijala, Martijn C. Willemsen, and Joseph A. Konstan. 2018. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing (SAC '18), 10 pages. DOI: 10.1145/3167132.3167281
This paper introduces and evaluates MovieExplorer, an interactive exploration tool designed to use the data available in a traditional ratings-based recommender system to provide an interactive interface more suited to user exploration and fulfillment of short-term recommendation needs. A field deployment with 1,950 users showed that users found the tool useful for a variety of exploration and short-term recommendation tasks, even preferring it to existing interfaces for several tasks. Experimentation with several design features found that the actual user navigation algorithms were significant (user satisfaction was lower for algorithms with faked controls) and that offering positive and negative feedback options led to increased feedback and user retention.
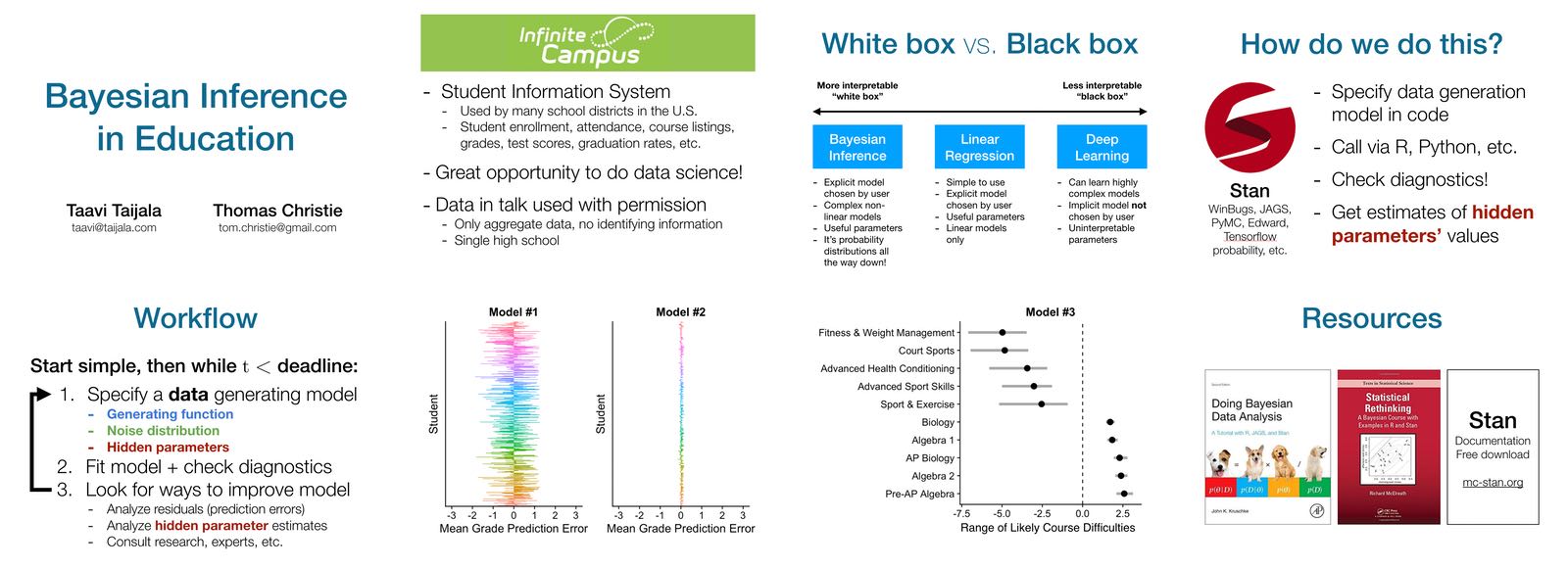
Taavi Taijala and S. Thomas Christie. Presented at MinneAnalytics' Big Data Tech. Minneapolis, MN, June 5, 2018.
Student learning, course effectiveness, and teacher grading difficulty are examples of critical educational factors that cannot be directly observed and must be inferred. In this talk, we show how to use Bayesian inference in the educational domain to estimate these quantities, and discuss how we can use state space models to update our estimates as the underlying properties change over time. In the process, we introduce Stan, a probabilistic programming framework, and discuss best practices in model evaluation and model comparison.
5 years experience in:
Ability to creatively apply a wide range of ML techniques to solve diverse problems, such as time series forecasting, recommendation, and classification. Experience implementing state-of-the-art algorithms as described in literature.
Strong knowledge of bayesian inference, modeling, and parameter estimation. Proficient in state-of-the-art bayesian modeling tools, like Stan and JAGS. Experience performing both model comparisons and model convergence diagnostics.
Formal education in math and statistics, including calculus I, II, III and linear algebra. Multiple years experience in frequentist and bayesian statistics.
Skilled at designing and coding interactive tools and apps using standard web technologies, such as HTML, CSS, Javascript, python, and Java.